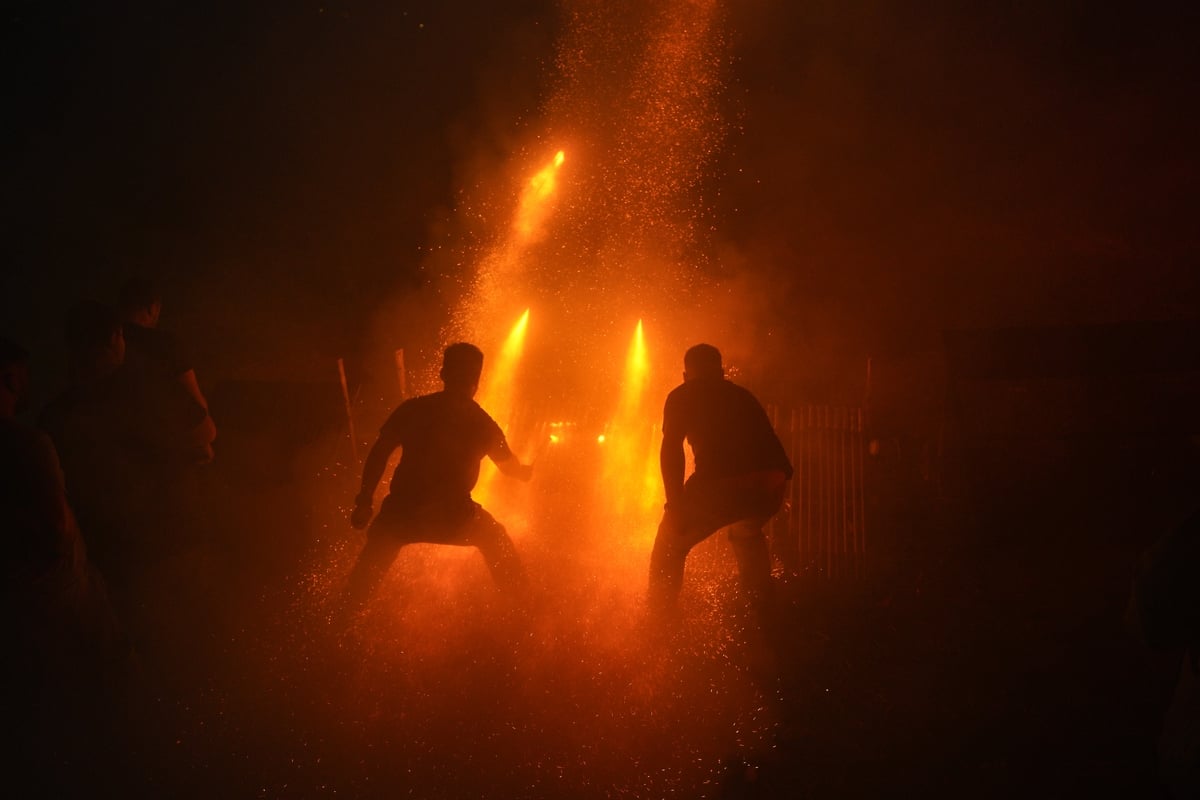Η παρουσία στις διαπραγματεύσεις του Ουίλλιαμ Μπερνς, επικεφαλής της CIA, από την Παρασκευή, δείχνει πόσο επιθυμούσε η Ουάσιγκτον την επίτευξη της εκεχειρίας.
Το διαδίκτυο βρίθει πλέον από εικονογραφικά σημάδια –pixelated εικόνες, emoji και άλλους τυπογραφικούς κώδικες– που σηματοδοτούν την πολιτική διαφωνία.
Εικόνες καταστροφής και θρήνου στη Ράφα, την πόλη στο νότιο τμήμα της Λωρίδας της Γάζας, όπου είχαν καταφύγει περίπου 1,4 εκατομμύρια εκτοπισμένοι Παλαιστίνιοι. Με τον ισραηλινό στρατό να έχει διατάξει…
Το υπουργείο Άμυνας της Βρετανίας (MoD) δέχτηκε κυβερνοεπίθεση, με τις υποψίες να στρέφονται στην Κίνα. Το χακάρισμα στόχευε ένα σύστημα μισθοδοσίας του Υπουργείου Εξωτερικών που περιλαμβάνει ονόματα και τραπεζικά στοιχεία…
Για μία νέα εξαετή θητεία στην προεδρία της Ρωσίας ορκίστηκε ο Βλαντίμιρ Πούτιν. Την τελετή της ορκωμοσίας μποϊκόταραν οι ΗΠΑ και πολλές χώρες της Ευρωπαϊκής Ένωσης, λόγω του πολέμου στην…
Για πρόκληση για τη διεθνή κοινότητα κάνει λόγο το υπουργείο Εξωτερικών, αναφερόμενο στην απόφαση των τουρκικών αρχών για την έναρξη της λειτουργίας της Μονής της Χώρας ως μουσουλμανικού τεμένους. Όπως…
«Εμείς προσπαθούμε να αυξήσουμε τους φίλους μας. Δεν έχουμε κανένα πρόβλημα που δεν μπορούμε να λύσουμε με τις χώρες της περιοχής μας. Πιστεύουμε ότι δεν υπάρχει πόρτα που δεν μπορεί…
Τον στόχο του να καταστήσει την Ελλάδα μία χώρα της προόδου περιέγραψε ο Στέφανος Κασσελάκης μιλώντας στο OPEN, υποστηρίζοντας ότι αν κερδίσει τις βουλευτικές εκλογές θα δημιουργήσει μια «πραγματικά άριστη…
Με τον δήμαρχο Σερίφου, Κωνσταντίνο Ρεβίνθη, συναντήθηκε την Τρίτη στο κυκλαδίτικο νησί ο πρόεδρος του ΠΑΣΟΚ-Κινήματος Αλλαγής, Νίκος Ανδρουλάκης. Συζήτησαν για τα προβλήματα που αντιμετωπίζουν οι μόνιμοι κάτοικοι, την υποβάθμιση…
Για «προαποφασισμένη επίθεση» που «καταρρίπτει και τα τελευταία προσχήματα των συμμάχων του Ισραήλ, μεταξύ των οποίων και η ελληνική κυβέρνηση, που στηρίζουν την βαρβαρότητα εναντίον των Παλαιστινίων» κάνει λόγο το…
Tης Κωνσταντίνας Τσούνη, ερευνήτριας, Τμήμα Επικοινωνίας, Μέσων και Πολιτισμού, Πάντειο Πανεπιστήμιο ΩΣ ΓΥΝΑΙΚΟΚΤΟΝΙΑ χαρακτηρίζεται η πλέον ακραία μορφή έμφυλης βίας,…
Δεν έχει τέλος η ανθρώπινη τραγωδία στη Λωρίδα της Γάζας. Τη νύχτα της Κυριακής προς Δευτέρα σε νέα ισραηλινή αεροπορική επίθεση στη Ράφα – την πόλη, στην οποία έχουν καταφύγει…
Ως τζαμί αναμένεται να λειτουργήσει από σήμερα ο βυζαντινός ναός της Μονής της Χώρας στην Κωνσταντινούπολη, μετά από απόφαση του Τούρκου προέδρου Ταγίπ Ερντογάν, που ανατρέπει απόφαση το υπουργικού συμβουλίου…
Τα πτώματα τριών τουριστών που βρέθηκαν σε ένα πηγάδι στο βορειοδυτικό Μεξικό είχαν όλα τραύματα από σφαίρες στο κεφάλι, ανακοίνωσαν οι αρχές. Οι Αυστραλοί αδερφοί Τζέικ και Κάλουμ Ρόμπινσον, 30…
«Αυξημένη προσοχή» συνιστούν οι ΗΠΑ στους πολίτες τους που επισκέπτονται την Γερμανία, λόγω του κινδύνου τρομοκρατικών ενεργειών, ειδικά ενόψει της διεξαγωγής του Ευρωπαϊκού Πρωταθλήματος Ποδοσφαίρου. Αντίστοιχη προειδοποίηση έχει ήδη εκδώσει…
Η Κίνα επεκτείνει ραγδαία το πυρηνικό της οπλοστάσιο. Υπό την ηγεσία του Σι Τζινπίνγκ, το Πεκίνο βρίσκεται σε καλό δρόμο να συγκεντρώσει 1.000 πυρηνικές κεφαλές έως το 2030, από περίπου…
Ο παραδοσιακός ρουκετοπόλεμος στο Βροντάδο της Χίου ( Evangelia Koukouna / SOOC)
ΠΑΓΚΟΣΜΙΑ ΗΜΕΡΑ STAR WARS
May the 4h be with you
Η Παγκόσμια Ημέρα Star Wars γιορτάστηκε σε όλο τον κόσμο από τους φίλους του σύμπαντος του Τζορτζ Λούκας. May the Force be with you. ( REUTERS/Athit Perawongmetha)